Scraping Major League Soccer Statistics

Introduction¶
I've long wanted to start applying more of the skills I've learned during the GalvanizeU Data Science Masters Program to sports related data. I am particularly drawn to using it to analyze soccer as I have grown up playing soccer my entire life. The other exciting thing about applying data science to soccer is that the sport has traditionally only had very simple statistics recorded such as shots, goals, fouls, percentage of possession. As a result the statistics available were not very good predictors of which team would win a game.
This has started to change recently because more data is being collected about events occuring on the field and the specific positions of those events. In addition, the positions of all players on the field at all times can now be tracked. However, this also presents a challenge because much of this data is not available publicly.
Great! So, uh, what data are you going to use?¶
I don't actually have access to the positional data so we are going to start much simpler on this project. Being a fan of Major League Soccer I've chosen to start by creating my dataset using a web scraper to retrieve all player statistics from mlssoccer.com.
This weekend is also the start of the 2016 season so the timing couldn't be better!
Here is an example of the type of page we are going to be scraping data from.
The Project¶
This is the first step in what should be a fun mini project of exploring Major League Soccer statistics. However, first we have to get the data to analyze!
Imports and Dependencies¶
The first step to doing any web scraping is identifying what tools you will need. In this case I have taken advantage of two open source python libraries to retrieve the source code for each url:
Requests: Used for fetching URL's with some wrapper code to make our lives easier by not having to manually add query strings or form-encoding.
BeautifulSoup: BeautifulSoup is awesome. It doesn't actually retrive the web page (which is why we need Requests), but when provided source code from a web page it allows us to easily and intuitively extract information from the page using classes, tags, and other standard html and css standards.
import requests
from bs4 import BeautifulSoup
# Additional required libraries
from collections import defaultdict
from itertools import product
import json
Establish Your Roots¶
The first step to being able to succesfully scrape a website is to view the source code. There are quite a few ways to do this, but most of the modern browsers come with developer tools which make our lives easier.
Here is an example of the webpage above with the Chrome Developer Tools utility up to be able to see the source code.
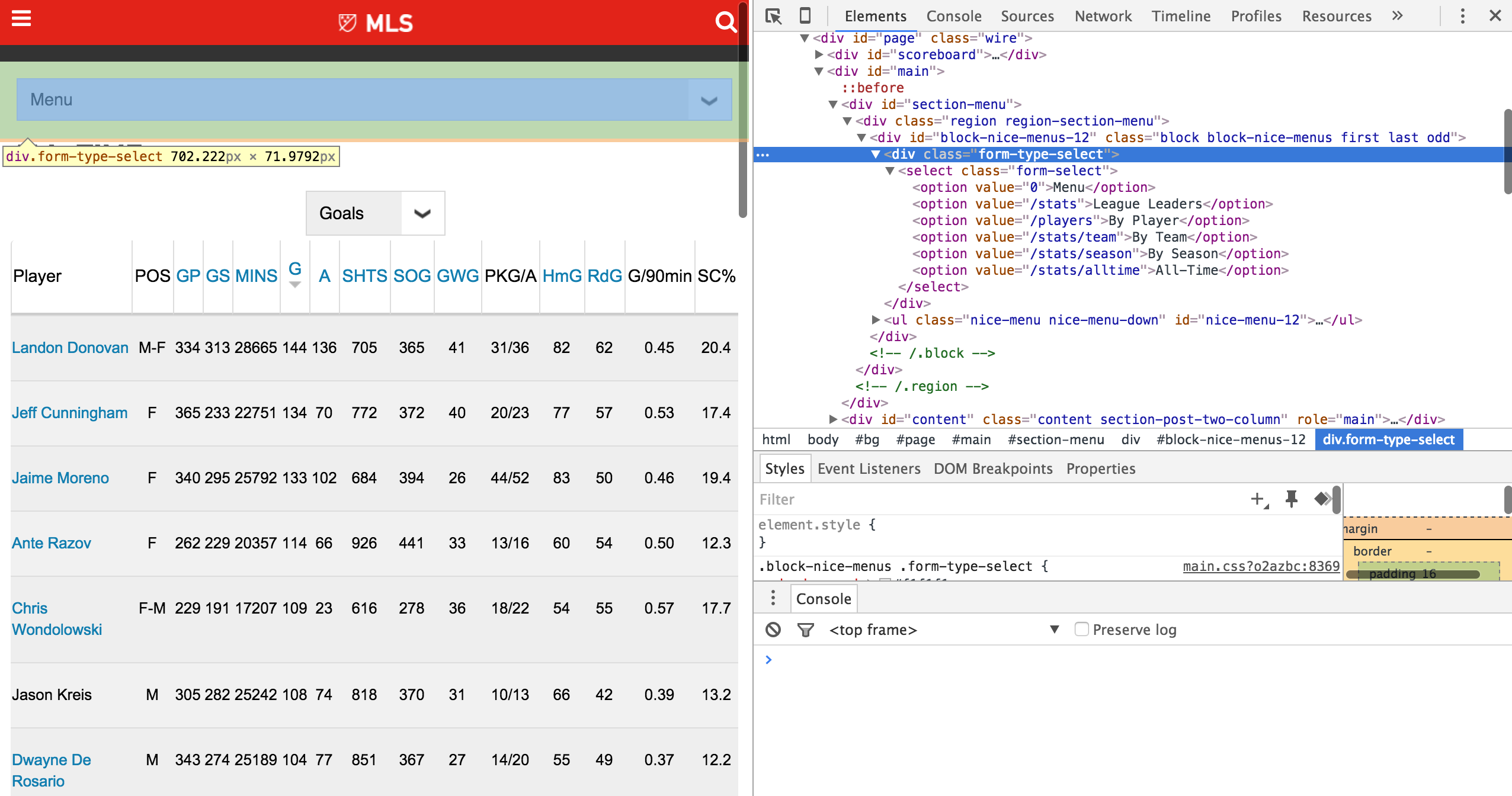
One of the coolest things it does for us is to highlight the elements of the webpage and the code associated with those elements so we aren't looking for the needle in the source code haystack. Thanks Google Chrome!
I always prefer starting with this step before jumping straight into html parsing through BeautifulSoup. The more experienced you are the easier it is to jump right into the code, but sometimes slowing down and looking at it through the developer tools allows you to catch any gotchas early on.
A quick analysis tells us that we have 4 primary elements to keep track of in order to crawl through each webpage and scrape:
1.Primary Menu (This will be used as our endpoint.)

2.Secondary Menu
3.The form containing the statistics
4.The page number of the form
We've now reached a major milestone! There is enough information for us to combine the root URL and endpoint to scrape the root page and collect details about the form itself.
# Assign ROOT_URL first. We will later append endpoints and parameters.
ROOT_URL = 'http://www.mlssoccer.com/stats/'
# Because the top menu just provides different views of the same
# statistics we can simply our code by specifying a single endpoint
# and ignoring all others. I have chosen to use 'seasons'.
ENDPOINT = 'seasons'
# Get the html source using requests
r = requests.get(ROOT_URL + ENDPOINT)
# Use BeautifulSoup to parse the raw html and return it as a nested data structure
soup = BeautifulSoup(r.text,'html.parser')
Congratulations! We have now scraped our first page, but the fun is only just getting started.
Build Out The Branches¶
This is where having already looked at the source code using the browser developer tools pays off for us. We already know exactly what elements we are looking for: the primary menu, the secondary menu, the form table, and the page numbers.
We also already hardcoded the primary option to use 'seasons' as our endpoint, so next we need to scrape the root page to get a list of all the possible options for the secondary menu.
# Build lists of all possible menu options
franchises = []
years = []
season_types = []
groups = []
for menu in soup.select('select[name]'):
if menu['name'] == 'franchise':
franchises = [(option['value'], option.contents[0])
for option in menu.find_all('option')
if option['value'] != 'select']
elif menu['name'] == 'year':
years = [option['value']
for option in menu.find_all('option')
if option['value'] != 'select']
elif menu['name'] == 'season_type':
season_types = [option['value']
for option in menu.find_all('option')
if option['value'] != 'select']
elif menu['name'] == 'group':
groups = [option['value']
for option in menu.find_all('option')
if option['value'] != 'select']
# Using the list of all menu options, create a list of all different parameter combinations
menu_options = [season_types, groups, years]
params_list = [{'season_type':params[0], 'group': params[1], 'year': params[2]}
for params in list(product(*menu_options))]
We also need to keep in mind the navigation elements of the form. When accessing the form through a browser we see that each form page shows 25 records. To see the next 25 records we have to go to the next page, but how do we know when to stop?
There are definitely multiple ways to handle form paging in our automated script. For instance, we could add exception handling to catch 404 errors when we attempt to access the page number after the last page or even be a little more clever about checking the data we've scraped to exit once we start getting blank or invalid records. In this case I decided to retrive the last page element from the source could and store it to use as the maximum value for our page loop. (One thing I didn't know when I originally wrote this script was that the last page is generic across all variations of the form. As a result there are cases were we get multiple form pages of blank records. If I have the need to revisit this script in the future I would try to be more efficient here.)
# Get the last page with data, adding one to account for starting from 0.
last_page = int(soup.select('.pager-last')[0].a['href'].split('=')[1]) + 1
Harvest The Fruits of Our Labor¶
So far we've primarily been focused on collecting information that will help us crawl the forms and scrape the data we want. Now we get to take advantage of that work and perform the actual scraping.
We don't want to have to rescrape the site every time we want to work with the data so I'm also writing the data to disk as json files. I also made the decision to write the results out as multiple files initially, but will most likely end up combining the data into a single file during preprocessing. I could be a little loose here because all together we're only dealing with about 5.5 MB.
# We did the hard work of building out all the parameter combinations, so
# now all we need to do is loop through those combinations and scrape the form
# to get the relevant statistics.
for params in params_list:
# Initialize a dictionary we'll use to store the data as we
# scrape it from the form.
data = defaultdict(list)
# We want to persist the scraped data so we have it locally and don't
# need to scrape it again each time we want to work with it.
fname = params['season_type'] + '_' + params['year'] + '_' + params['group']
print 'Scraping... {}'.format(params)
# Loop through every page of the form to collect the individual statistics.
for page in xrange(last_page):
# The one element we didn't include in our parameter list earlier was
# variations which include the page numbers. We could do that, but
# I think separating the paging into its own loop adds clarity.
params['page'] = page
# Requests will retrive the source code of a webpage given the URL.
# However, we also want to pass in the parameters which requests
# will append to the path so we get to the exact data we want.
r = requests.get(url + ENDPOINT, params=params)
# Remember, BeautifulSoup doesn't retrieve the URL source code for
# us which is why we needed requests. Now that we have the source
# code we can pass it to BeautifulSoup for parsing.
soup = BeautifulSoup(r.text, 'html.parser')
# Loop through each row of statistics
for item in soup.select('tr[class]'):
# Loop through each column in the row (e.g. 'GP')
for column in item.find_all('td'):
# Last page spans all statistics, so we don't always need to
# loop through all pages. Admittedly, this is a bit of a hack.
if column.contents[0] == 'Stats Unavailable':
break
# Use the column title as our key
key = column['data-title']
# In most cases the player data includes a link to the player profile,
# so we want to split that out to make our lives easier later.
if key == 'Player':
# Break out player name from profile link (if it exists).
try:
profile = column.a['href']
name = column.a.contents[0]
# When there isn't profile link.
except:
profile = None
name = column.contents[0]
data['Profile'].append(profile)
data['Name'].append(name)
else:
value = column.contents[0]
data[key].append(value)
# Write our newly scrapped data to disk as a json file.
with open('./data/' + fname + '.txt', 'w') as f:
json.dump(data, f)
Summary and Next Steps¶
...and there you go. We've now scrapped all the Major League Soccer statistics and can start really getting into the data to explore.
I hope this motivated you to go have fun scraping data for your own projects. Web scraping can be a little tedius at times, but in most cases it isn't too bad.
Feel free to use this script to get the data and join me while I explore and poke it with the proverbial stick to see what we can learn. Everything from this post (including the code and instructions for running it) is available from my github acount.